Membersihkan Data
Berkenalan dengan OpenRefine
![]()
OpenRefine (atau sebelumnya dikenal sebagai Google Refine) merupakan alat bantu yang paling wahid untuk merapihkan data yang berantakan. Alat bantu ini menyajikan beragam fitur yang berguna untuk membersihkan data, mengatasi inkonsistensi, mendeteksi duplikasi, memanipulasi teks dan lain sebagainya. OpenRefine tersedia untuk berbagai sistem operasi seperti Windows, Mac OS dan Linux.
OpenRefine merupakan perangkat lunak bebas, didistribusikan dibawah lisensi BSD. Pembaca yang tertarik berkontribusi dapat memperoleh kode sumber via Github.
Memasang OpenRefine
OpenRefine berjalan di atas platform Java. Jadi pastikan komputer Anda telah terpasang Java runtime yang tersedia di http://www.java.com/download/. Untuk pemasangan OpenRefine sendiri tahapannya sangat mudah tergantung sistem operasi yang Anda miliki.
Windows
- Unduh paket ZIP (
google-refine-xx.zip), - Ekstrak isian paket ke sistem direktori lokal Anda,
- Klik-ganda
openrefine.exeuntuk menjalankan OpenRefine.
Mac
- Unduh paket DMG (
google-refine-xx.dmg), - Buka paket instalasi dan seret ikon OpenRefine ke direktori
Application, - Klik-ganda OpenRefine untuk menjalankannya.
Linux
- Unduh paket TAR (
google-refine-xx.tar.gz), - Ekstrak isian paket ke sistem direktori lokal Anda,
- Buka aplikasi Terminal dan ketik perintah
./refineuntuk menjalankannya.
Ketika dijalankan, OpenRefine akan ditampilkan di atas browser Web. Perhatikan bahwa aplikasi ini tidak membutuhkan koneksi Internet walaupun dijalankan memakai browser, kecuali fitur rekonsiliasi data yang memang menggunakan layanan ekternal.
Secara bawaan, OpenRefine tersedia di URL http://localhost:3333/ atau http://127.0.0.1:3333.
Memulai Proyek Baru
Memulai sebuah proyek baru di OpenRefine selalu diawali dengan pemilihan sumber data yang akan dimuat. Pilih Create Project untuk membuat proyek baru seperti yang ditampilkan dalam gambar di bawah ini.
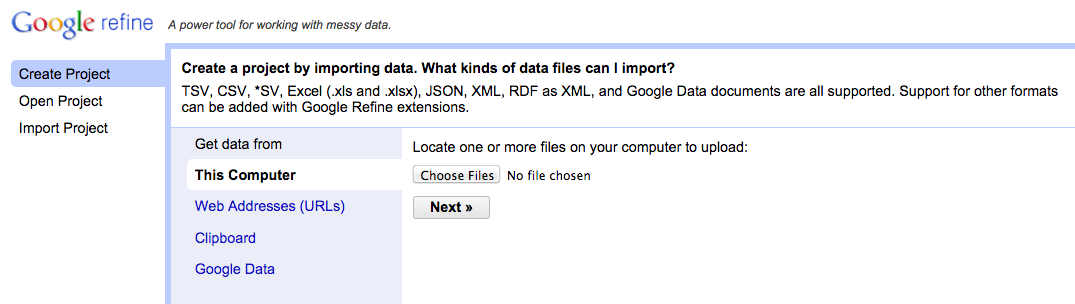
OpenRefine menyediakan beberapa pilihan untuk mendapatkan sumber data, antara lain:
- This Computer: Menggunakan data yang tersimpan di lokal komputer,
- Web Addresses (URL): Menggunakan data yang terdapat di jejaring,
- Clipboard: Mengambil dari buffer data sementara yang berisikan salinan data,
- Google Data: Mengakses data yang berasal dari Google Spreadsheet atau Fusion Table.
Setelah memilih sumber data, aplikasi akan memperlihatkan hasil pemuatan data untuk pengguna melakukan peninjauan. Apabila tidak terdapat masalah, pengguna dapat kemudian memberikan nama proyek dan mengakhiri perintah pembuatan proyek baru.
Format data
OpenRefine mendukung beberapa format data yang umum dipakai, antara lain:
- Comma-Separated Values (CSV), Tab-Separated Values (TSV), dan format *SV lainnya,
- Dokumen Excel (XLS dan XLSX) dan Open Document Speadsheets (ODS),
- JavaScript Object Notation (JSON),
- eXtensible Markup Language (XML),
- Resource Description Framework dalam XML (RDF/XML),
- Line-based formats (LOG).
Pengguna dapat memasang modul ekstensi tambahan untuk memproses format-format data lainnya.
Mengenal Tampilan Utama
OpenRefine memiliki tampilan utama berupa presentasi data dalam bentuk tabular kolom dan baris.
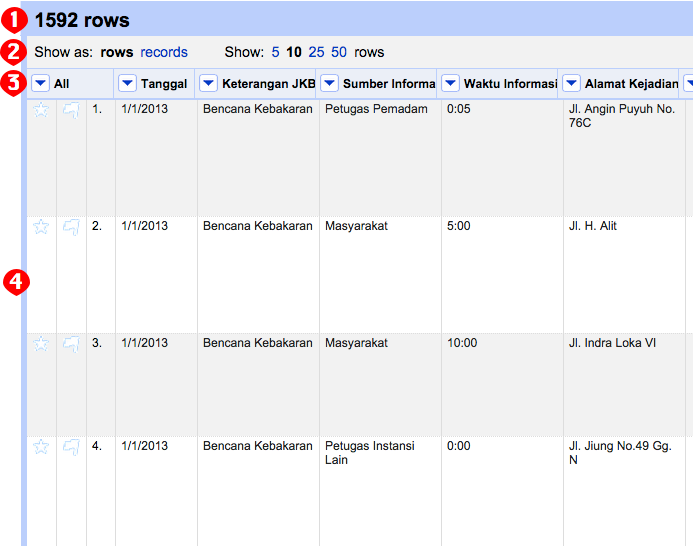
Terdapat empat bagian penting dari tampilan tersebut, antara lain:
(1) Total baris: Jumlah baris data yang berhasil dikenali dan dimuat oleh OpenRefine.
(2) - Pilihan tampilan: OpenRefine menyediakan pilihan 2 mode tampilan data yaitu rows dan records. Dalam mode rows atau baris, setiap baris adalah satu satuan unit data. Sedangkan dalam mode records atau rekaman, unit data disebutkan sebagai suatu objek yang dapat terdiri dari beberapa baris. Disamping itu, OpenRefine juga memberikan pilihan untuk menampilkan banyak baris atau rekaman per halaman untuk memudahkan penjelahan isian data.
(3) Kepala kolom dan menu: Penamaan kepala kolom diambil dari baris pertama sumber data. Apabila pada waktu pemuatan data opsi Parse next 1 line as column headers tidak dipilih maka penamaannya menjadi Column 1, Column 2, Column 3, dan seterusnya. Setiap kolom memiliki menu kolom yang dapat diakses melalui ikon segitiga di masing-masing kolom.
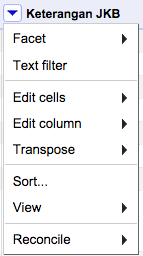
Secara bawaan, kolom paling kiri akan selalu bernama All dan terbagi dalam 3 subkolom: Star, Flag dan ID. Kolom Star dan Flag dapat dipakai untuk menandai baris-baris data yang spesial. Misalnya pemberian tanda Star dipakai untuk menandai baris data yang baik dan tanda Flag untuk baris data yang buruk.
(4) Isian data: Isian data atau sel data memuat nilai data.
Bekerja dengan Kolom
Kolom merupakan bagian terpenting di OpenRefine. Hampir dipastikan sebagian besar interaksi pengguna akan bermula dari pemilihan kolom dan penggunaan operasi terhadapnya. Kolom-kolom di OpenRefine dapat disesuaikan menurut kebutuhan pengguna seperti yang akan dijelaskan sebagai berikut:
Menyembunyikan kolom
OpenRefine akan selalu menampilkan kolom-kolom secara jelas terpampang. Hal ini terkadang dapat sangat mengganggu untuk jumlah kolom yang sangat besar. Untungnya pengguna dapat menyembunyikan satu per satu kolom untuk sementara waktu memakai perintah View > Collapse. Alternatif lain, pengguna dapat menyembunyikan semua kolom dengan pengecualian menggunakan perintah View > Collapse all other columns.
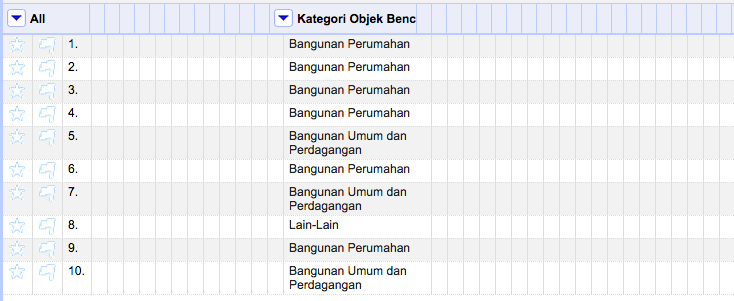
Gambar di atas memperlihatkan hasil eksekusi perintah tersebut dimana kolom Kategori Object Bencana dipilih untuk dikecualikan. Pengguna dapat menampilkan kembali kolom yang disembunyikan dengan mengklik kepala kolom yang bersangkutan. Untuk memperlihatkan semua kolom yang tersembunyi gunakan menu kolom pertama All dan pilih View > Expand all columns.
Memindahkan kolom
Terkadang akan sangat membantu apabila urutan kolom dapat diubah sesuai kebutuhan, misalnya untuk melakukan perbandingan langsung antar kolom. Perintah ini dapat ditemukan di menu kolom, kemudian Edit column > Move column (posisi), dimana pemindahan posisi dapat diarahkan ke sebelah kiri, ke sebelah kanan, ke posisi terdepan atau ke posisi paling belakang.
Apabila pengguna ingin benar-benar mengubah struktur kolom secara keseluruhan maka gunakan menu kolom pertama All dan pilih Edit columns > Re-order / remove columns…. Perintah ini akan membuka jendela dialog dimana semua nama kolom akan ditampilkan secara lengkap.
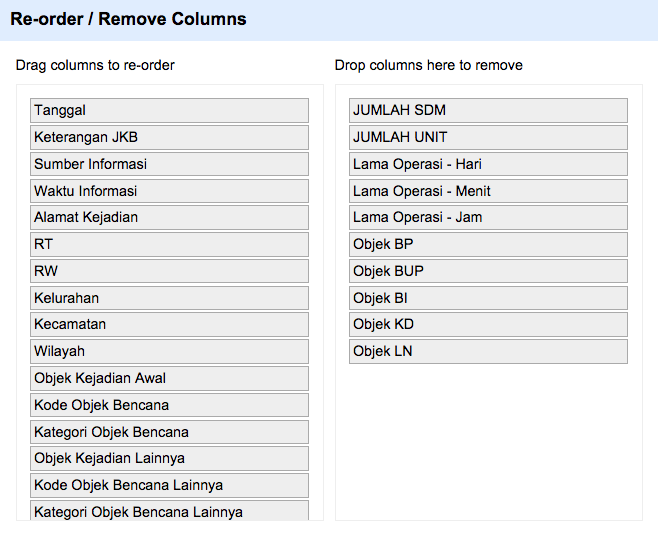
Untuk menghapus kolom, pindahkan kolom tersebut ke lajur kanan Drop columns here to remove. Untuk mengatur ulang urutan kolom, posisikan kolom tersebut secara bebas di lajur kiri Drag columns to re-order.
Mengganti nama kolom
Untuk mengganti nama kolom gunakan perintah Edit column > Rename this column di menu kolom yang bersangkutan.
Menghapus kolom
Untuk mengganti nama kolom gunakan perintah Edit column > Remove this column di menu kolom yang bersangkutan.
Mengenal Undo/Redo
OpenRefine akan selalu menyimpan perintah-perintah operasi sebagai catatan histori proyek. Fitur ini sangat berguna untuk mengulang kembali tahapan proses kerja jika disadari terjadi kesalahan. Untuk melihat histori proyek, klik tab Undo / Redo di dekat sudut kiri atas.
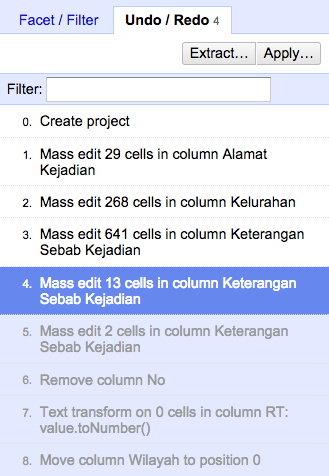
Cara kerja histori proyek ini sangat intuitif. Untuk mengulang tahapan proses sebelumnya (undo), pilih urutan proses secara mundur. Dan sebaliknya apabila ingin memulihkan tahapan proses ke langkah terakhir (redo), pilih urutan proses secara maju. Penting diketahui bahwa OpenRefine hanya menyimpan perintah-perintah operasi yang mengubah isian data. Perintah-perintah untuk keperluan visual seperti menyembunyikan kolom, mengurutkan data atau penggunaan facet tidak akan tersimpan di histori proyek.
Mengurutkan Data
Data yang terurut dapat memudahkan analisis data. OpenRefine memiliki fitur mengurutkan data di menu kolom Sort…. Perintah ini akan membuka jendela dialog yang akan mengarahkan mekanisme pengurutan data.
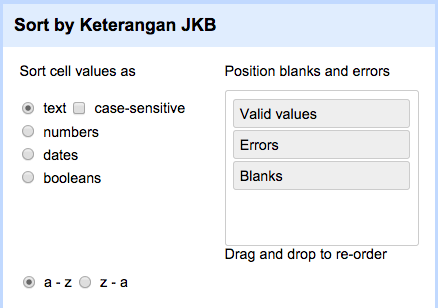
Pengguna dapat memilih 2 opsi pengurutan data (secara menanjak atau menurun) sesuai tipe data yang dimiliki kolom tersebut:
- Text: secara alfabetikal (a-ke-z) or alfabetikal terbalik (z-ke-a). Pengguna dapat menambahkan opsi case-sensitive agar huruf kapital diperhitungkan dalam pengurutan data.
- Numbers: dari angka terkecil dulu atau dari angka terbesar dulu.
- Dates: dari tanggal terlampau dulu atau tanggal teraktual dulu.
- Booleans: false kemudian true atau true kemudian false.
Lebih lanjut pengguna dapat mengatur urutan jenis isian data pada hasil keluaran terakhir di panel Position blanks and errors. Salah satu contoh penggunaannya, data yang tidak valid (atau Errors) diurutkan terlebih dahulu untuk memudahkan pendeteksian kesalahan, diikuti dengan data yang valid (atau Valid values) dan diakhiri dengan data yang kosong (atau Blanks).
Mengurutkan data secara permanen
OpenRefine menyediakan fitur mengurutkan data secara permanen dimana urutan baris data yang baru akan benar-benar disimpan dan menggantikan peletakannya yang lama. Fitur ini berada di menu Sort di panel utama. Perhatikan bahwa menu ini baru akan muncul apabila perintah menu kolom *Sort… pernah dilakukan.
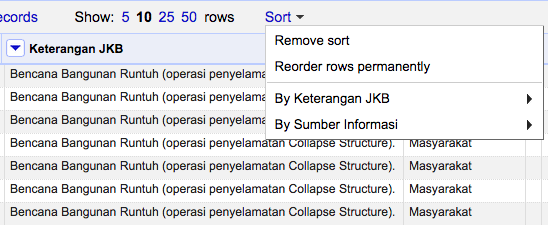
Di dalam menu Sort akan diperlihatkan kolom-kolom yang pernah mengeksekusi perintah pengurutan data. Gambar di atas memperlihatkan kolom Keterangan JKB dan Sumber Informasi sebagai asal pengurutan data. Jika pengguna ingin membatalkan pengurutan data, gunakan menu Sort > By (column name) > Remove sort. Akhirnya untuk membuat pengurutan data secara permanen, pilih menu Sort > Reorder rows permanently. Perhatikan bahwa perintah pengurutan ini akan disimpan di dalam histori proyek.
Memilah Data dengan Facet
OpenRefine memiliki fungsi facet yang akan memudahkan pembacaan data secara terkelola. Dengan facet pengguna dapat memilah data berdasarkan pengelompokannya dan menampilkan sebagian data yang dibutuhkan. Pada praktiknya, pengguna dapat menjalankan beberapa facet sekaligus untuk mendapatkan pemilahan data yang tepat guna.
Berikut ini adalah beberapa facet yang umum dipakai di OpenRefine:
Facet teks
Facet ini berguna untuk melihat sekilas kumpulan isian data teks yang sejenis dan frekuensinya. Fitur ini terdapat di menu kolom Facet > Text facet.
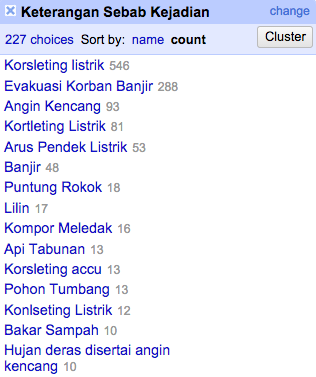
Gambar di atas memperlihatkan hasil pengoperasian facet teks di kolom Keterangan Sebab Kejadian. Pengguna dapat mengurutkan hasil facet di menu panel Sort by menurut nama atau frekuensinya. Hasil di atas jika diurutkan menurut frekuensinya jelas terlihat bahwa Korsleting listrik menempati urutan pertama dengan 546 kejadian, diikuti Evakuasi Korban Banjir sebanyak 288 kejadian, Angin kencang dengan 93 kejadian, dan seterusnya.
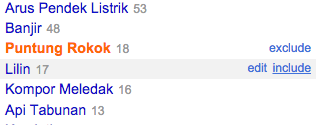
Pengguna dapat langsung memilah data dengan mengklik label nama di jendela facet. Apabila ingin menambahkan label kedua dan seterusnya gunakan pilihan include dan OpenRefine akan menambahkan baris data sesuai label nama tersebut. Contoh di atas memperlihatkan pemilahan data berdasar label Puntung Rokok atau Lilin sebagai penyebab kejadian.
Facet numerik
Sesuai dengan namanya facet ini dikhususkan untuk kolom bertipe data numerik. Fitur ini terdapat di menu kolom Facet > Numeric facet.

Facet ini akan menghasilkan grafik histogram yang menampilkan penyebaran frekuensi data untuk setiap data numerik. Gambar di atas memperlihatkan grafik histogram untuk kolom Jumlah Unit dimana dapat dibaca isian data terbanyak berada di kisaran nilai 1 sampai 5. Seperti halnya facet teks, pengguna dapat memilah data berdasarkan isian data numerik dengan mengubah jendela rentang nilai seperti yang ditampilkan dalam gambar sebagai berikut:
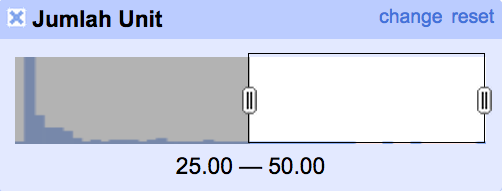
OpenRefine akan menampilkan isian data jumlah unit yang memiliki kisaran angka 25 sampai 50.
Facet tanggal
Facet ini mirip dengan facet numerik hanya saja dikhususkan untuk kolom bertipe data tanggal. Fitur ini terdapat di menu kolom Facet > Timeline facet.
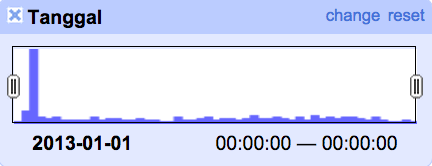
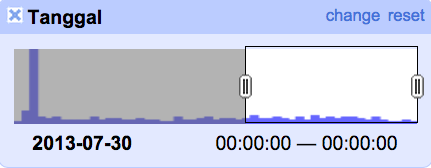
Facet ini akan menghasilkan grafik histogram yang menampilkan penyebaran frekuensi data untuk setiap data tanggal. Gambar di atas memperlihatkan grafik histogram untuk kolom Tanggal. Pengguna dapat memilah data berdasarkan isian tanggal dengan mengubah jendela rentang nilai seperti contoh di bawah, memilah data dari tanggal 30 Juli 2013 sampai tanggal terakhir.
Mendeteksi Duplikasi
Memiliki data duplikat adalah sangat tidak efisien. Menyimpan data-data ini dapat memboroskan tempat dan menciptakan keambiguan terhadap dataset yang dimiliki. Mendeteksi data duplikat bisa sangat rumit karena selain membutuhkan pengetahuan terhadap data itu sendiri, pendeteksiannya masih perlu dilakukan secara manual. OpenRefine menyediakan beberapa fitur bantuan yang dapat memudahkan proses pendeteksian ini.
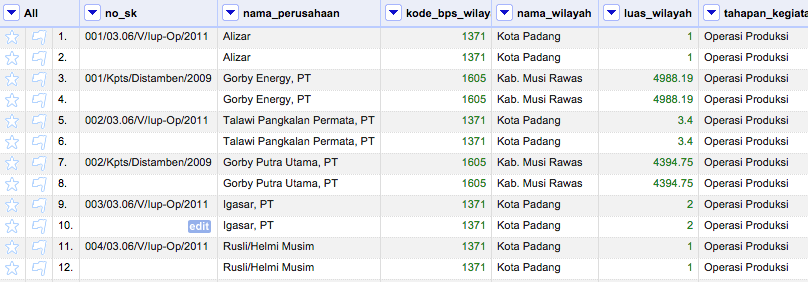
Pendeteksian awal data duplikat bisa diawali dengan penelusuran kolom ID atau kode identitas sejenisnya. Kolom ini memiliki arti intrinsik sebagai penanda unik setiap baris data. Apabila ditemukan duplikasi nilai di kolom ini maka dapat diduga terdapat data duplikat. Cara termudah untuk melihat informasi ini adalah dengan menggunakan facet teks di menu kolom Facet > Text facet di kolom ID tersebut.
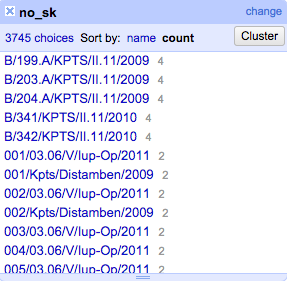
Gambar di atas memperlihatkan beberapa data yang berpotensi memiliki duplikasi di kolom no_sk karena memiliki jumlahan lebih dari satu. Cara lain untuk mendeteksi duplikasi adalah dengan menggunakan facet duplikasi di menu Facet > Customized facets > Duplicates facet di kolom yang sama.
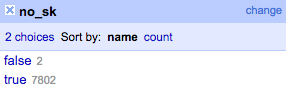
Gambar di atas memperlihatkan hampir keseluruhan isian kolom memiliki data duplikat. Hal ini diketahui karena sejumlah besar data bernilai true (dibaca: memiliki duplikat? ya/true). Klik nilai true tersebut untuk menampilkan data-data duplikat saja. Pengguna dapat menggunakan simbol Flag atau Star di kolom All sebagai penanda duplikasi.
Menghapus Duplikasi
Sebelum menghapus data duplikat pengguna perlu menelusuri secara teliti isi data-data tersebut. Cara tercepat adalah dengan mengambil sampel data dan mengamati isinya. Hasil pengamatan dari contoh sebelumnya disimpulkan bahwa hanya data yang berjumlah dua yang diyakini memiliki baris data yang identik. Sedangkan data-data duplikat lainnya berpotensi memiliki baris data yang tidak semuanya identik.

Gambar di atas memperlihatkan nomor SK 406 tahun 2009 yang memiliki daftar 3 perusahaan tambang yang berbeda. Karena temuan ini nomor SK tidak bisa dijadikan patokan andalan untuk pendeteksian data duplikat.
Untuk mengatasi masalah ini dapat digunakan fitur Facet by choice counts di jendela facet. Sekadar mengulang, kolom no_sk sebelumnya telah diaplikasikan perintah facet teks untuk menghitung jumlahan di setiap nilai datanya. Fitur Facet by choice counts ini terdapat di antrian paling bawah jendela facet sehingga pengguna perlu menggulung sampai akhir. Penggunaan fitur ini akan membuka jendela facet baru yang memuat grafik histogram.

Atur rentang nilai di jendela facet histogram pada kisaran 2 di kursor kanan untuk memilah data yang memiliki kembaran dua nomor SK.
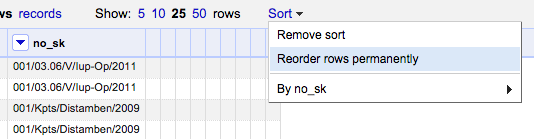
Langkah berikutnya adalah mengurutkan data di kolom no_sk agar kembaran data saling berdekatan. Buat pengurutan data ini menjadi permanen dengan memilih Sort > Reorder rows permanently di menu panel utama. Langkah ini penting untuk menunjang langkah berikutnya berjalan dengan benar.
Setelah data diurutkan, pilih menu kolom Edit cells > Blank down untuk kolom no_sk. Secara seketika semua data duplikat menghilang dan perhatikan di jendela facet teks semua nomor SK hanya tersisa satu.
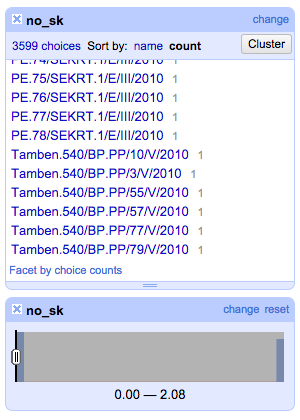
Perhatikan perintah tadi sama sekali tidak menghapus data duplikat tetapi hanya menghilangkan dari tampilan. Perintah Blank down hanya mengganti setiap isian data identik berikutnya dengan sel kosong atau blank. Untuk memperlihatkan sel-sel kosong tersebut, buang facet histogram menakai ikon x di sudut kiri atas jendela facet.
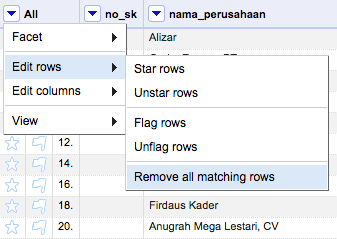
Untuk dapat benar-benar menghapus data duplikat, pilih menu Facet > Customized facets > Facet by blank di kolom no_sk. Jendela facet baru akan muncul dan kemudian klik nilai true untuk menampilkan hanya baris-baris data dengan nomor SK bernilai kosong. Akhirnya di kolom pertama All pilih menu Edit rows > Remove all matching rows untuk menghapus data-data duplikat tersebut.
Fungsi Transformasi Umum
OpenRefine menyediakan beberapa fungsi umum untuk mentransformasi data. Fungsi-fungsi tersebut dapat ditemukan di menu kolom Edit cells > Common transforms.

Penjelasan untuk masing-masing fungsi adalah sebagai berikut:
-
Trim leading and trailing whitespace digunakan untuk menghapus karakter spasi (termasuk tab) di awal dan di akhir isian data. Hal ini penting diperhatikan agar data yang identik tidak akan dibedakan oleh karena karakter spasi yang tidak perlu.
-
Collapse consecutive whitespace akan menghapus karakter spasi yang berlebihan akibat kesalahan pengetikan. Kesalahan ini umum ditemukan di kolom yang mengandung kalimat yang panjang.
-
Unescape HTML entities akan mengubah karakter kode HTML menjadi huruf baca yang lazim ditulis. Contohnya huruf é akan dikodekan (escape) sebagai
éatauédi HTML. Dengan fungsi ini kode-kode tersebut akan diubah ulang (unescape) ke karakter huruf yang tepat. -
To titlecase akan mengubah penulisan kata-kata mengikuti penulisan judul. Contoh Kab. lima puluh kota akan ditransformasi menjadi Kab. Lima Puluh Kota.
-
To uppercase akan mengubah penulisan kata-kata memakai huruf kapital semua. Contoh Contoh Kab. lima puluh kota akan ditransformasi menjadi KAB. LIMA PULUH KOTA.
-
To lowercase akan mengubah penulisan kata-kata memakai huruf non-kapital semua. Contoh Contoh Kab. lima puluh kota akan ditransformasi menjadi kab. lima puluh kota.
-
To number akan mengkonversi tipe isian data menjadi numerik.
-
To date akan mengkonversi tipe isian data menjadi tanggal. Isian data akan ditampilkan mengikuti format
yyyy-mm-ddThh:mm:ssZ. -
To text akan mengkonversi tipe isian data menjadi teks.
-
Blank out cells akan menghapus isian data menjadi sel kosong.
Pengguna dapat mengkostumisasi fungsi transformasi sesuai kebutuhannya dengan menggunakan fitur Custom text transform dengan memilih di menu kolom Edit cells > Transform….
Mengatasi Inkonsistensi Data
Tidak jarang inkonsistensi dapat ditemukan di tabel data. Hal ini berkaitan dengan proses awal penulisan data yang tidak dikontrol, baik oleh manusia atau sistem komputer. Kesalahan-kesalahan yang mungkin terjadi antara lain kesalahan ejaan, penulisan huruf kapital sembarangan, penggunaan nama-nama secara bebas dan ketidakseragaman penulisan akibat minim standarisasi. Akibatnya data sulit dikelompokkan secara efektif dan hasil analisis tidak maksimal.
OpenRefine menyediakan sebuah fitur yang dinamakan clustering untuk membantu memperbaiki kesalahan-kesalahan tersebut. Fitur ini dapat ditemukan di menu kolom Edit cells > Cluster and edit…. OpenRefine kemudian akan menampilkan jendela dialog yang menyediakan pilihan metode pengelompokkan dan fungsi-fungsi algoritmanya. Pada awal penggunaan, metode key collision dan fungsi fingerprint akan otomatis terpilih. Gambar di bawah memperlihatkan hasil clustering atau pengelompokan data untuk kolom Kelurahan.
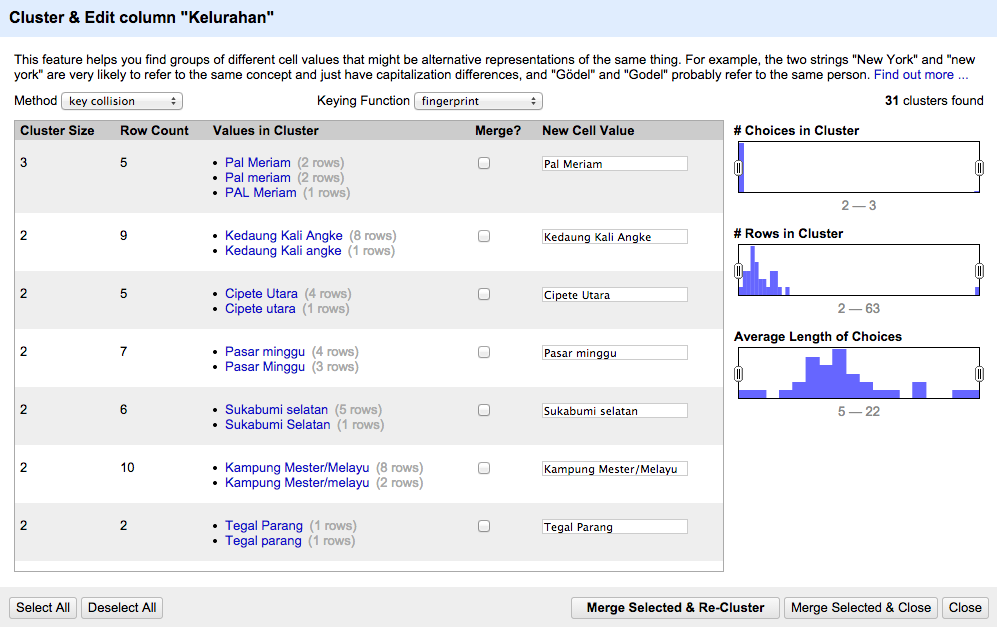
Di bagian kiri terdapat tabel hasil pengelompokan dengan 5 kolom utama. Kolom Cluster Size menampilkan jumlah grup yang berhasil teridentifikasi di kolom Values in Cluster. Kolom Row Count memberikan jumlah baris data yang membentuk kelompok-kelompok data tersebut. Di kolom Values in Cluster ditampilkan isian-isian data yang memiliki kemiripan beserta jumlah baris datanya. Sebagai contoh, penulisan kelurahan Pal Meriam memiliki 3 kemiripan nama yaitu Pal Meriam, Pal meriam dan PAL Meriam, dimana masing-masing memiliki 2 baris, 2 baris dan 1 baris. Pengguna dapat menentukan pemakaian nama yang seragam dengan mengklik isian nama yang dikehendaki. Secara otomatis, nama tersebut akan terisi di kolom New Cell Value dan kotak pilihan di Merge? akan tercentang. Menggunakan informasi yang terkumpul di tabel ini pengguna dapat secara cepat menentukan keseragaman isian data guna meminimalisir inkonsistensi.
Di bagian kanan terdapat 3 grafik histogram untuk keperluan penyaringan hasil pengelompokkan. Masing-masing histogram memiliki hubungan dengan kolom-kolom di tabel sebelah. Grafik pertama # Choices in Cluster akan menyaring banyak grup yang tertera di kolom Cluster Size. Grafik kedua # Rows in Cluster akan menyaring banyak baris data yang terhitung di kolom Row Count. Dan terakhir grafik Average Length of Choices akan menyaring berdasarkan panjang karakter di kolom Values in Cluster. Fitur penyaringan ini sangat berguna apabila pengguna ingin memfokuskan penyelesaian inkonsistensi di sub-data tertentu.
Sangat dianjurkan untuk memeriksa semua inkonsistensi secara manual agar penyelesaiannya tepat sasaran. Pilih Merge Selected & Re-Cluster untuk memulai perintah penyeragaman dan sebagai tambahan OpenRefine akan kembali menjalankan algoritma clustering untuk mencari kembali kemiripan data, jika ada. Pengguna pun dapat memilih untuk segera menutup jendela dengan Merge Selected & Close.
Metode and algoritma
Secara teknis, OpenRefine menawarkan dua metode clusterint yaitu key collision dan nearest neighbor. Metode key collision akan memetakan setiap isian data ke slot tertentu menurut pengkodean karakter yang unik didapat dari fungsi pengkodean keying function. Cara kerjanya adalah pengelompokan terbentuk ketika beberapa isian data dipetakan ke slot yang sama karena memiliki kode karakter yang sama (disebutkan bahwa isian-isian data tersebut memiliki kemiripan). Algoritma fungsi pengkodean yang disediakan antara lain: fingerprint, ngram-fingerprint, metaphone3 dan cologne-phonetic.
Sedangkan metode nearest neighbor menggunakan fungsi jarak atau distance function dengan membandingkan setiap isian data. Semakin dekat nilai jarak menandakan kemiripan antar isian data tersebut. Algoritma fungsi jarak yang disediakan antara lain: levenshtein dan PPM.
Mentransformasi Data
OpenRefine menyediakan mekanisme untuk mengganti atau mentransformasi data secara cepat dan serentak. Fitur ini terdapat di menu kolom Edit cells > Transform…. Setelah terpilih, jendela dialog transformasi akan muncul dimana pengguna dapat mengisi perintah di Expression dan melihat hasil eksekusi ekspresi tersebut di panel Preview langsung di bawahnya.
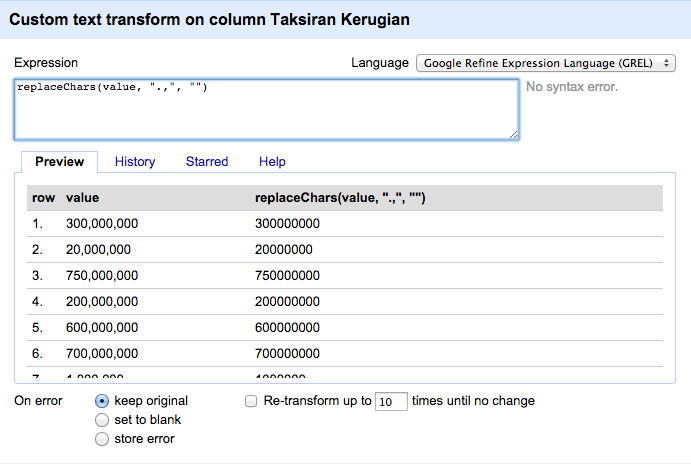
Bagian terpenting dari fitur ini adalah bahasa ekspresi transformasi. Ekspresi ini mengandung suatu perintah yang menginstruksikan OpenRefine untuk mengubah isian data. OpenRefine memakai bahasa ekspresi bernama General Refine Expression Language (GREL). Selain itu OpenRefine juga mendukung beberapa bahasa lain seperti Jython dan Clojure.
Materi pelatihan ini hanya akan membahas bahasa ekspresi GREL. Karena kami juga ingin menjaga tingkat kesulitan materi ini dalam kisaran untuk semua orang maka tidak semua perintah ekspresi akan dijabarkan secara detail di materi sini. Pembaca yang ingin mengetahui spesifikasi lengkap GREL dapat membacanya di http://github.com/OpenRefine/OpenRefine/wiki/Google-refine-expression-language.
Memecah Data
Terkadang dalam sebuah tabel ditemukan kolom-kolom yang mengandung beragam informasi. Contohnya, kolom Alamat terdapat informasi nomor RT/RW, nama kota, nam provinsi, kode pos dan sebagainya. Atau kolom Kontak terdapat nomor telepon dan alamat email sekaligus. Pada kasus tertentu ada baiknya jika informasi-informasi tersebut dapat dipisahkan dan memiliki kolomnya masing-masing.
OpenRefine menyediakan fitur memecah data di menu kolom Edit column > Split into several columns…. Setelah dipilih, jendela dialog akan muncul sebagai berikut:
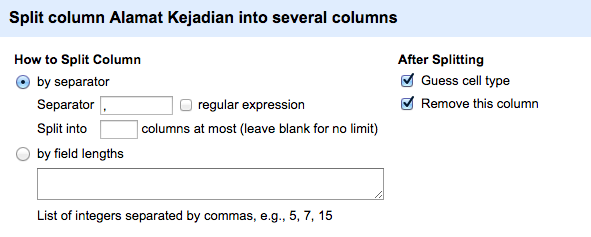
Terdapat 2 pilihan mekanisme pemecahan data. Cara pertama adalah by separator dimana pengguna dapat menentukan tanda pemisah yang digunakan untuk memecah data. Atau cara kedua by field lengths dimana pemisahan berdasarkan posisi karakter yang telah ditentukan. Metode ini akan sangat berguna untuk isian data yang memiliki struktur yang baku, seperti kode KTP atau nomor surat. Pengguna dapat menambahkan operasi pasca pemecahan data seperti penentuan tipe data dan penghapusan kolom asal.
Perhatikan bahwa OpenRefine akan menamakan kolom-kolom yang terbentuk baru memakai urutan penomoran sederhana. Sebagai contoh, ketika data di kolom Alamat dipecah menjadi 4 bagian maka secara otomatis kolom-kolom baru akan dinamai Alamat 1, Alamat 2, Alamat 3 dan Alamat 4. Pengguna dapat menamai ulang kolom-kolom tersebut menggunakan fitur penggantian nama kolom.
Menukar Posisi Kolom ke Baris
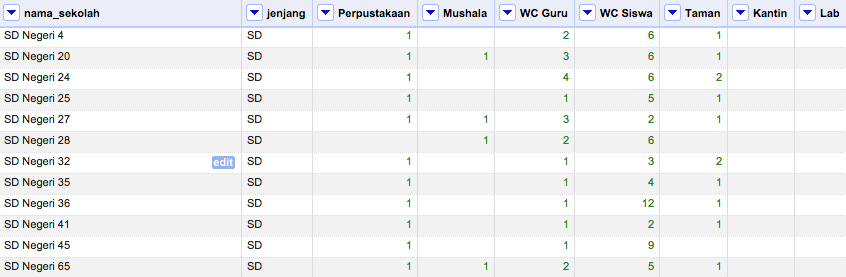
Terkadang data yang tersusun dalam baris dan kolom belum tentu memiliki struktur yang optimal. Salah satu contoh kasusnya adalah di data survei atau penelitian. Data jenis ini dapat memiliki sejumlah dimensi atau parameter pencatatan. Akan tetapi terkadang tidak semua objek observasi memerlukan kolom-kolom dimensi tersebut. Akibatnya terdapat banyak sel data yang kosong yang membuat struktur tabel tidak optimal. Selain itu kehadiran sel data kosong dapat menimbulkan keraguan dalam melakukan analisis data. Gambar di bawah menampilkan contoh data pencatatan sarana-prasarana sekolah yang memiliki banyak kekosongan.
Untuk mengatasi hal ini, langkah terbaik yang dapat dilakukan adalah dengan menukar posisi kolom-kolom tersebut menjadi baris. Fitur ini dapat ditemukan di menu kolom Transpose > Transpose cells across columns into rows….
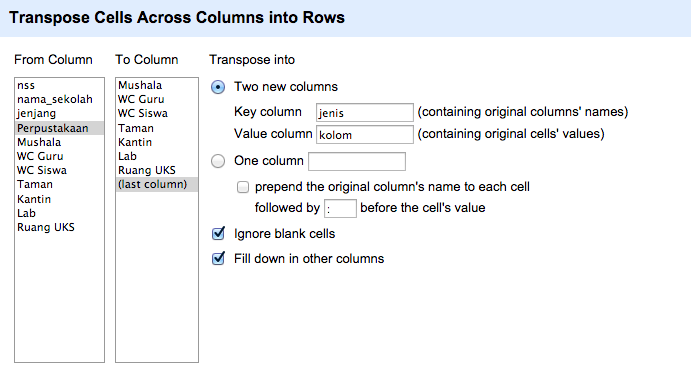
Gambar di atas memperlihatkan jendela dialog transpose dimana pengguna diharuskan memilih kolom pertama untuk From Column dan kolom terakhir untuk To Column. Kemudian kolom-kolom yang berada diantara kedua kolom awal tersebut akan ditransposisi atau dipindah posisinya menjadi baris.
Hasil akhir operasi pemindahan ini dapat diatur memakai opsi berikutnya. Jika dipilih opsi pertama Two new columns maka nama-nama kolom yang akan ditransposisi akan menjadi isian data di Key column dan nilai-nilai kolom tersebut akan menjadi isian data di Value column. Pengguna dapat memberi nama untuk kedua kolom tersebut sesuai keinginan. Alternatif lain adalah jika opsi kedua One column dipilih maka nama-nama kolom dan nilainya akan disimpan dalam satu kolom baru dalam bentuk teks key-value, misal Perpustakaan: 1, Mushala: 1, WC Guru: 2. Pengguna dapat menentukan nama kolom baru tersebut beserta tanda pemisah key-value.
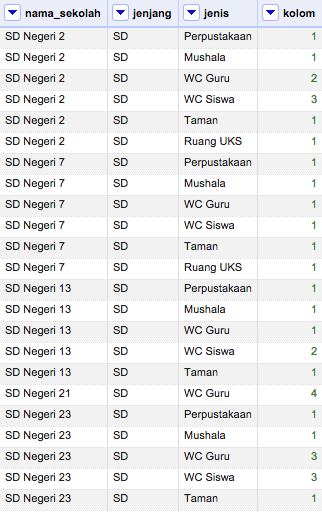
Opsi tambahan lainnya adalah Ignore blank cells dan Fill down in other columns. Jika opsi pertama dipilih maka kolom yang memiliki sel kosong akan dihiraukan sehingga tidak akan terbentuk baris data baru. Jika opsi kedua dipilih maka setiap baris baru kolom-kolomnya akan dilengkapi isian data yang dibutuhkan. Gambar di atas memperlihatkan hasil akhir transposisi untuk kolom-kolom nama sarana-prasarana disertai pemilihan kedua opsi tersebut.